BOM - PnP Parser
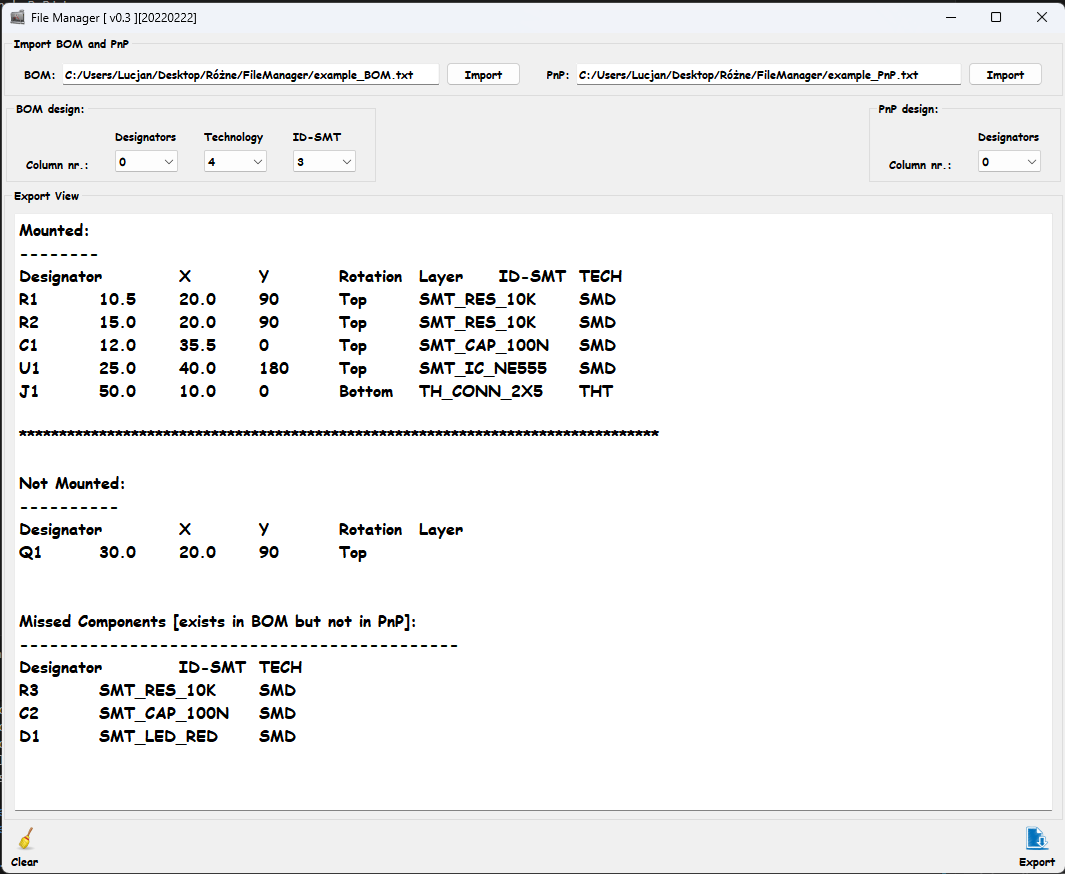
BOM - PnP Parser to lekki program desktopowy służący do automatycznego porównywania, walidacji oraz scalania plików BOM (Bill of Materials) oraz PnP (Pick-and-Place / Centroid). Aplikacja pozwala na wczytanie plików tekstowych (.txt, .csv) o dowolnej strukturze kolumn, dopasowanie współrzędnych montażowych do parametrów technologicznych komponentów, a następnie automatyczny podział całości na trzy osobne, gotowe dla kontraktora pliki wyjściowe: elementy do montażu, elementy pominięte (brakujące w PnP) oraz elementy dodatkowe (brakujące w BOM). Wszystko kontrolowane z poziomu intuicyjnego interfejsu PyQt5.
🛠️ Stos Technologiczny (Tech Stack)
Aplikacja została napisana z naciskiem na minimalną liczbę zależności (zero zewnętrznych ciężkich bibliotek typu Pandas czy OpenPyXL), co gwarantuje natychmiastowe uruchamianie i pełną przenośność:
- Język i GUI:
**Python 3.8+**•**PyQt5**(okna, przyciski, listy rozwijane oraz zarządzanie zachowaniem interfejsu) - Silnik Prasujący (Parsing Engine):
**Pure Python**(obsługa plików tekstowych rozdzielanych tabulatorami\tlub przecinkami,przy użyciu wbudowanych mechanizmów Pythona) - Zarządzanie Stanem:
**QSettings**(zapamiętywanie ostatnio ustawionych pozycji okna aplikacji po jego zamknięciu) - Zarządzanie Ścieżkami:
**pathlib**(bezpieczne i wieloplatformowe operowanie na strukturze katalogów i plików wyjściowych)
📈 Po co to w ogóle powstało? (Zastosowanie i korzyści dla twórcy)
- Eliminacja błędów przedprodukcyjnych: Ręczne sprawdzanie, czy każdy rezystor lub kondensator z BOM ma przypisane współrzędne w pliku PnP (i odwrotnie), przy setkach elementów na płytce graniczy z cudem. Program robi to automatycznie w ułamek sekundy.
- Rozbijanie zgrupowanych elementów (Flattening): Programy CAD (np. Altium Designer) często grupują identyczne elementy w jednej linii BOM (np. jako
R1,R2,R3). Pliki PnP wymagają jednak osobnej linii dla każdego elementu. Aplikacja automatycznie "rozpłaszcza" te grupy, dopasowując dane indywidualnie dla każdego komponentu. - Dynamiczne mapowanie kolumn: Każdy program CAD generuje pliki w innym formacie. Dzięki dynamicznym listom rozwijanym użytkownik wskazuje, która kolumna odpowiada za designatory, technologię i kod montażowy (ID-SMT), dzięki czemu aplikacja obsłuży pliki z dowolnego oprogramowania.
- Automatyczny podział na 3 paczki wyjściowe:
- Mounted: Komponenty, które są na płytce i mają pełne dane montażowe z BOM.
- Not Mounted: Elementy obecne w pliku współrzędnych, ale niewyszczególnione w BOM (np. punkty testowe, znaczniki fiducial).
- Missed: Komponenty z listy BOM, których fizycznie zabrakło na współrzędnych PnP (np. elementy montowane ręcznie lub przeoczone w projekcie).
💡 Architektura i Wyzwania Inżynieryjne (Czyli jak to działa pod maską)
Projekt rozwiązuje kilka typowych problemów związanych z parsowaniem niespójnych struktur danych wejściowych w aplikacjach desktopowych.
1. Rozbijanie (spłaszczanie) zgrupowanych designatorów
- Wyzwanie: W plikach BOM wiele elementów o tej samej wartości zapisuje się jako jeden wiersz z kolumną designatorów w postaci
R1, R2, R3. Aby dopasować je do indywidualnych linii z pliku PnP (gdzieR1,R2iR3mają swoje osobne współrzędne X/Y), trzeba stworzyć mapę, w której kluczem jest pojedynczy designator. - Rozwiązanie: Podczas parsowania pliku BOM aplikacja wyszukuje przecinki w kolumnie oznaczeń. Jeśli je znajdzie, dzieli ciąg na pojedyncze indeksy za pomocą
.split(','), a następnie dla każdego z nich tworzy osobny wpis w słownikuBOM_dictz przypisanymi parametrami technologicznymi i montażowymi.
2. Dynamiczne indeksowanie kolumn
- Wyzwanie: Zamiast zmuszać użytkownika do modyfikacji plików przed uruchomieniem programu, aplikacja musi dynamicznie odczytywać indeksy kolumn. Kolumny w plikach wejściowych mogą być ułożone w dowolnej kolejności.
- Rozwiązanie: Program automatycznie analizuje nagłówek pliku wejściowego i wykrywa separator (
\tlub,), po czym dynamicznie generuje listę dostępnych indeksów kolumn w kontrolkach typuQComboBox. Wartości te są następnie przekazywane jako parametryDES_POS,ID_POSiTECH_POSdo funkcji parsującej, dzięki czemu dostęp do pól odbywa się bezpiecznie przez dynamiczny indeks tabeli.
3. Bezpieczne zapisywanie plików bez nadpisywania niespokrewnionych danych
- Wyzwanie: Wygenerowane pliki wyjściowe powinny zapisać się w tym samym katalogu co plik PnP, nie psując jego oryginalnej zawartości i przyjmując czytelne nazwy.
- Rozwiązanie: Przy pomocy biblioteki
pathlibsystem pobiera nazwę bazową oraz rozszerzenie pliku PnP, po czym konstruuje nowe ścieżki dodając odpowiednio sufiksy_mounted,_not_mountedoraz_missed. Następnie przy użyciu bezpiecznych metod zapisu plik po pliku zapisuje tylko te listy, które faktycznie zawierają jakiekolwiek dane.
💻 Przykłady Kodu (Code Snippets)
1. Konwersja pliku BOM na płaski słownik (Słownikowanie z podziałem grup)
Poniższy fragment modułu parsującego (`modules/my_parser.py`) pokazuje, jak program analizuje wiersze pliku BOM, automatycznie rozdziela zgrupowane przecinkami oznaczenia i tworzy ujednolicony słownik ułatwiający szybkie dopasowywanie danych:# modules/my_parser.py
def convert_BOM_to_dict(BOM: list, DES_POS: str, ID_POS: str, TECH_POS: str):
BOM_dict = dict()
if type(BOM) is list and DES_POS and ID_POS and TECH_POS:
DES_POS = int(DES_POS)
ID_POS = int(ID_POS)
TECH_POS = int(TECH_POS)
for i, row in enumerate(BOM):
row = row.strip()
if '\t' in row:
if i == 0: # Pomiń nagłówek
continue
columns = row.split('\t')
if DES_POS >= len(columns) or ID_POS >= len(columns) or TECH_POS >= len(columns):
continue
# Jeśli designatory są zgrupowane (np. R1,R2,R3)
if ',' in columns[DES_POS]:
designators = columns[DES_POS].split(',')
for designator in designators:
designator = designator.strip()
BOM_dict[designator] = {
'ID-SMT': columns[ID_POS],
'TECH': columns[TECH_POS]
}
else:
BOM_dict[columns[DES_POS]] = {
'ID-SMT': columns[ID_POS],
'TECH': columns[TECH_POS]
}
elif ',' in row and '\t' not in row:
if i == 0: # Pomiń nagłówek
continue
columns = row.split(',')
if DES_POS >= len(columns) or ID_POS >= len(columns) or TECH_POS >= len(columns):
continue
BOM_dict[columns[DES_POS]] = {
'ID-SMT': columns[ID_POS],
'TECH': columns[TECH_POS]
}
else:
continue
return BOM_dict
else:
return {}
2. Algorytm weryfikacji i generowania plików wynikowych
Funkcja porównująca plik PnP ze słownikiem BOM (`compare_PnP_with_BOM`). Zwraca ona trzy odseparowane od siebie struktury gotowe do zapisania na dysku:# modules/my_parser.py
def compare_PnP_with_BOM(PnP: list, BOM: dict, DES_POS: str):
PnP_mounted = []
PnP_not_mounted = []
PnP_missed = []
PnP_designators = []
BOM_designators = BOM.keys()
if type(PnP) is list and type(BOM) is dict and DES_POS:
DES_POS = int(DES_POS)
for i, row in enumerate(PnP):
if '\t' in row:
row = row.strip()
if i == 0:
# Dodanie nagłówków dla nowych plików wyjściowych
row_mounted = row + '\tID-SMT\tTECH\n'
PnP_mounted.append(row_mounted)
row += '\n'
PnP_not_mounted.append(row)
else:
designator = row.split('\t')[DES_POS]
PnP_designators.append(designator)
# Przypisz parametry montażowe, jeśli element istnieje w BOM
if designator in BOM_designators:
row += f"\t{BOM[designator]['ID-SMT']}\t{BOM[designator]['TECH']}\n"
PnP_mounted.append(row)
else:
row += '\n'
PnP_not_mounted.append(row)
elif ',' in row and '\t' not in row:
row = row.strip()
if i == 0:
row_mounted = row + ',ID-SMT\tTECH\n'
PnP_mounted.append(row_mounted)
row += '\n'
PnP_not_mounted.append(row)
else:
designator = row.split(',')[DES_POS]
if designator in BOM_designators:
row += f"\t{BOM[designator]['ID-SMT']}\t{BOM[designator]['TECH']}\n"
PnP_mounted.append(row)
else:
row += '\n'
PnP_not_mounted.append(row)
else:
continue
# Wykrywanie komponentów pominiętych w pliku PnP (brak współrzędnych)
for BOM_des in BOM_designators:
if BOM_des not in PnP_designators:
if len(PnP_missed) == 0:
PnP_missed.append('Designator\tID-SMT\tTECH\n')
row = f"{BOM_des}\t{BOM[BOM_des]['ID-SMT']}\t{BOM[BOM_des]['TECH']}\n"
PnP_missed.append(row)
return PnP_mounted, PnP_not_mounted, PnP_missed
else:
return [], [], []